I clearly remember the Win 3.1 operating system which was entirely built on top of MS-DOS. But when networking between computers became more common, Dos (or MS-DOS as it was known) started revealing its shortcomings as it is not a network operating system and was designed to be run on standalone machines. More over it did not have true multi-tasking, multi-user functionality. Recognizing these drawbacks, Microsoft decided to move on and built the Windows 95/98/NT/2000/XP OSes and gradually shifted base from a DOS based kernel to an entirely new network operating system as you see in Windows 2000/XP.
FreeDOS is a project which aims to recreate the magic of DOS and bring a truly free GPLed DOS encompassing all the characteristics of MS-DOS with lots of improvements thrown in. A couple of weeks back, FreeDOS developers released ver 1.0 of their OS. I downloaded the full CD ISO of FreeDOS from their website which was around 153 MB in size.
Since I have been using Linux as my operating system, I decided to install and use FreeDOS inside Linux by means of an emulator. In the past, I have used Qemu to run Damn Small Linux on my Ubuntu machine. And I was pleased with its performance. So I decided to use Qemu to run FreeDOS as well.
Qemu is an emulator which can be used to run a variety of OSes inside a host OS. It is well supported on the Linux platform with ports available for Windows and Mac OSX. Since Qemu is not installed by default on my Ubuntu machine, I had to install it first using the following command:
$ sudo apt-get install qemu
Once qemu was installed, I created a directory named freedos in the /opt/ path and moved the downloaded FreeDOS ISO file into it.
$ mkdir /opt/freedos
$ cp fdfullcd.iso /opt/freedos/.
Preparing an image to hold the FreeDOS
In Linux, everything is considered a file. So the hard disk, the monitor, the keyboard, mice are all recognised as files by the OS. By the same logic, it is possible to install programs and entire OSes into a file, the only requirement being the file should be large enough to store what ever is intended to be stored in it.
My intention was to install FreeDOS into a file and boot it using QEMU. I roughly estimated that 400 MB space is ample for installing and working in FreeDOS and so created a raw file named freedosfile.img roughly of size 400 MB using the dd command as follows:
$ cd /opt/freedos
$ dd if=/dev/zero of=freedosfile.img bs=1024 count=400000
400000+0 records in
400000+0 records out
409600000 bytes (410 MB) copied, 18.9476 seconds, 21.6 MB/s
Now a long listing of the directory /opt/freedos gave the following output:
$ ls -l /opt/freedos
-rw-r--r-- 1 ravi ravi 160184320 2006-09-05 02:11 fdfullcd.iso
-rw-r--r-- 1 ravi ravi 409600000 2006-09-12 10:38 freedosfile.img
Installation of FreeDOS
To initiate the installation of FreeDOS, I used the following command:
$ qemu -cdrom fdfullcd.iso -hda freedosfile.img -boot d
In the above command, -cdrom flag points to the ISO image of FreeDOS, -hda option denotes the hard disk to which I passed the name of the just created image (400MB) and finally -boot flag takes different options one of which 'd' denotes to boot from the CD-ROM.
 Fig: FreeDOS installation boot screen
Fig: FreeDOS installation boot screen
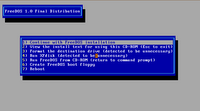 Fig: Another installation screenshot
Fig: Another installation screenshot
I was shortly presented with a beautiful splash screen featuring the FreeDOS mascot - 'Fd Fish', and I was provided a menu which among other options prompted me to boot from the CD-ROM. I pressed enter and I was provided a second menu which gave me options to initiate the FreeDOS installation or boot the live CD. At this stage if you are in two minds about installing FreeDOS, you can continue booting from the CD and in a few seconds will be placed in a FreeDOS shell. But since my intention was to install the OS, I chose the first option which is to install to hard disk using freedos setup.
Without going into undue details, let me give a run down of the installation process:
Installation steps for FreeDOS
- Select your language and keyboard layout.
- Prepare the hard disk for FreeDOS 1.0 final by running XFDISK. You can also create a floppy boot disk at this juncture.
Since the hard disk that freedos recognises is actually a file freedosfile.img which I passed via the command line, I chose to create a single primary partition encompassing the whole file (disk). Once the partition was created, pressing F3 wrote the changes and prompted me to restart the computer - which of course is the emulator Qemu. The right thing to do here is to press Yes and the same boot process takes place as earlier and in a short time I was provided with a menu prompt asking to format the hard disk (the file) with fat32 file system. - Next the installer prompts to continue with the installation which includes :
- agreeing to an end user licence (GPL)
- installing the packages. Here I had the option of providing an alternate path to install, the default path being 'C:\fdos'.
The FreeDOS OS is split into 10 packages each pertaining to a particular aspect of the OS. They are as follows:
- base - Essential DOS utilities which reproduce the functionality of MS-DOS
- compress - Free file compression and decompression utilities (7zip, arj, bzip2, cabextract, gzip, tar, zoo ...)
- driver - Free drivers for network cards and usb
- edit - A collection of editors (emacs, vim, pg, setedit, ospedit)
- games - A good choice of free DOS games - Doom, Solitare, BumpNJump, nethack, tetris...
- gui - Gem Desktop (Very nice)
- lang - Free compilers and assemblers (Pascal,C,Basic,assembler,Fortran, debuggers,make tool...)
- media - Free multimedia applications (cdrtools, ogg vorbis, mpxplay,lame ...)
- net - Networking programs (wget, VNC, SSH client, lynx, arachne, mail client, wattcp - a free TCP/IP stack for DOS).
- util - Free file, directory and other utilities (fprot anti virus, locate, head, du, cal, dos32ax, tail, tee, 4dos, uptime ...)
It is prudent to select all the packages to enjoy the full functionality of FreeDOS. Next I was provided a list of programs from each package where I could fine tune my choice of programs. More specifically, FreeDOS ships with two kernels - the stable one called 'sysx' and the unstable kernel named 'unstablx' and I could choose one from the other. The unstable kernel has support for Enhanced Mode Win3.1 and some DOS programs require this to work properly. So I selected the unstable kernel and the copying of files started.
All in all, it took about 15-20 minutes to install all the packages. Then FreeDOS started configuring the parameters. And I was prompted to choose a packet driver. There is a packet driver for Qemu provided which I selected . Following which I was prompted to install the OpenGEM GUI.
Post installation, FreeDOS starts configuring certain aspects and asks a couple of questions such as the address of the mailserver, the email id and a few other parameters.
Starting to use FreeDOS in GNU/Linux
Once installation was over, I booted FreeDOS in GNU/Linux using the following command:
$ qemu -hda freedosfile.img -boot c
... and shortly I was placed into the C:\> prompt. I would like to clarify that the above command will not start FreeDOS with networking enabled. For that, I had to put in some extra efforts and configure a tun-tap device, the steps of which are the topic for a separate article.
And yes, to have access to the floppy drive from within FreeDOS, I used the command as follows:
$ qemu -hda freedosfile.img -fda /dev/fd0 -boot c
What I like most about FreeDOS is the number of additional commands which have been included in it apart from the basic ones that were originally available in DOS. Linux users will be endeared to find tools such as head, tail, cal, ls, tar, gzip, bzip2, lynx, wget and many more ported to FreeDOS. Not only that FreeDOS comes bundled with a utility called 4Dos which adds many additional features to the bland Dos shell such as command line history, command completion and so on. Gem Desktop is a real beauty and will bring some relief to the GUI fanatics among us.
 Fig: Mine game in progress
Fig: Mine game in progress
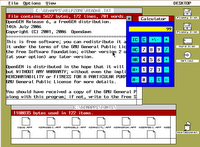 Fig: Open Gem Desktop
Fig: Open Gem Desktop
While on the topic of applications bundled with FreeDOS, a special mention needs to be made about Arachne web browser. This is (in my knowledge) the one and only web browser developed for DOS which is capable of displaying both text as well as images. It also extends as a desktop and allows one to access the files on the hard disk. It supports most protocols supported by any modern web browser which includes http, ftp, irc, smtp, pop3, finger, gopher, find ....and so on (see the image below).
 Fig: Arachne Web Browser
Fig: Arachne Web Browser
What is the motive for running FreeDOS when you have Linux ?
Now this is a question which most Linux users will ponder when faced with deciding to try out FreeDOS. The number one reason for using FreeDOS in my opinion is the enormous collection of applications available which run on DOS - many of them which were shareware at one point of time, now having been released as freeware. I still find small businesses running point-of-sale billing applications written in Foxpro using a low end 486 machine running MS-DOS. And these machines are prime candidates for running FreeDOS. Then there are the horde of
classic games which have no other equivalents found in any other operating systems. These reasons alone should be sufficient to persuade a person in installing and trying out FreeDOS on his machine. And installing and running it using Qemu makes it possible to, figuratively speaking, have the cake and eat it too.


 Fig: Front and backside of the PC
Fig: Front and backside of the PC Fig: The actual size of the PC
Fig: The actual size of the PC