

I am sure many of you will agree with me if I tell you that regular expressions are an integral part of all Posix operating systems. So what exactly are regular expressions ?
Regular expressions are characters that also include symbols which when used in a group, convey a special meaning to the shell. Broadly speaking, there are a few frequently used characters which are interpreted by the shell in a special way. They are as follows:
? - Question mark is used to mean a character repeated at most one time. That is 0 or 1 times.
* - Asterisk means the preceding character is repeated any number of times.. - A dot signifies any character.
^ - The beginning of the line
$ - End of the line
\ - Used when you want to represent the special characters literally. For example, to show '*', I can use '\*' which tells the shell not to interpret the literal.
For example, a regular expression 'ap?le*' will select the following strings:
aplee
aple
aleee
but not 'apple' or 'appplee' because 'p' can occur only 0 or 1 times.
Usually, people are a bit confused the first time they have to use regular expressions. I was, the first time I used them.
For those who find learning regular expressions a real chore, there is a very useful utility called kregexpeditor which is bundled with Linux running KDE. This utility can be used effectively to come up to date with regular expressions. See figure below.
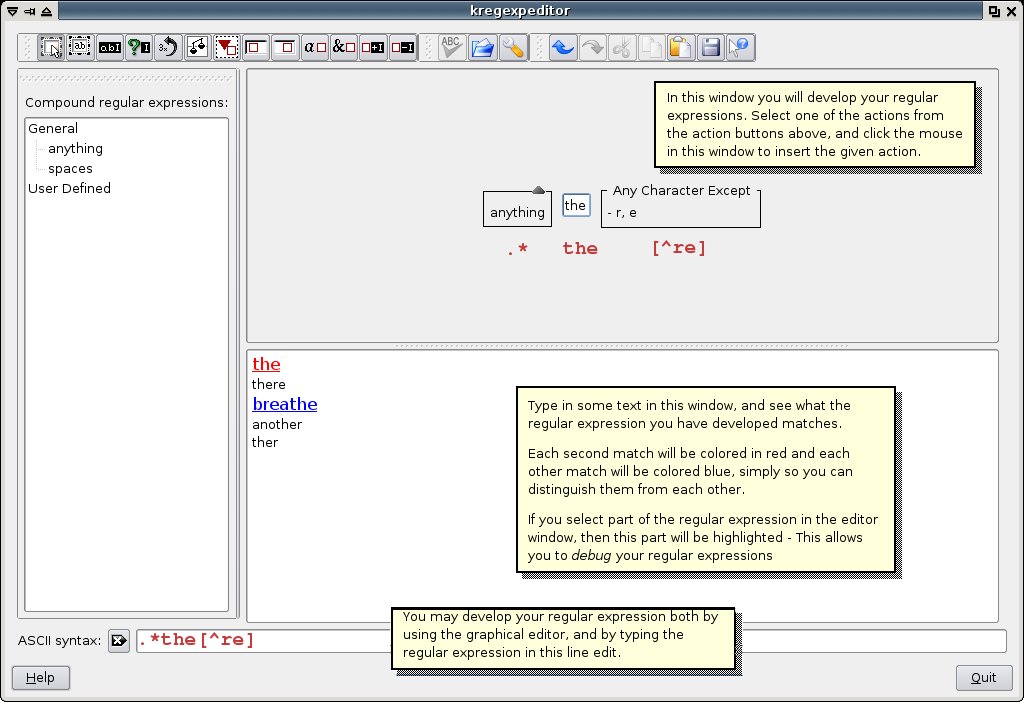 Fig: KRegExpEditor interface (Click on picture)
Fig: KRegExpEditor interface (Click on picture)kregexpeditor has a very intuitive interface and contains both an inbuilt graphical editor, a verification window as well as a command line edit where one can try out different combinations of regular expressions. For example, try figuring out for yourselves what the following regular expression selects ...
\b[A-Z0-9._%-]+@[A-Z0-9-]+\.[A-Z]{2,4}\b Hint: Open up kregexpeditor and enter the above regular expression into the line edit box labeled Ascii Syntax. And you will get a graphical representation of what this string expands to in the upper portion of the editor.
No comments:
Post a Comment